Algorithm Analysis
1. Kindle Substring Search
Exploring how Amazon Kindle leverages advanced string processing algorithms including Suffix Trees, Suffix Arrays, and the KMP Algorithm to enable lightning-fast text search across millions of books, providing readers with instant access to any content within their digital library.
Understanding String Search Algorithms
Amazon Kindle processes over 12 million books with billions of words, requiring sophisticated string search algorithms to deliver instant search results. When readers search for quotes, references, or specific content, Kindle's search engine must efficiently locate matches across massive text collections while maintaining responsive performance on resource-constrained e-reader devices.
The combination of Suffix Trees, Suffix Arrays, and KMP algorithms enables Kindle to perform complex pattern matching operations with optimal time complexity, supporting features like full-text search, phrase detection, and content recommendations.
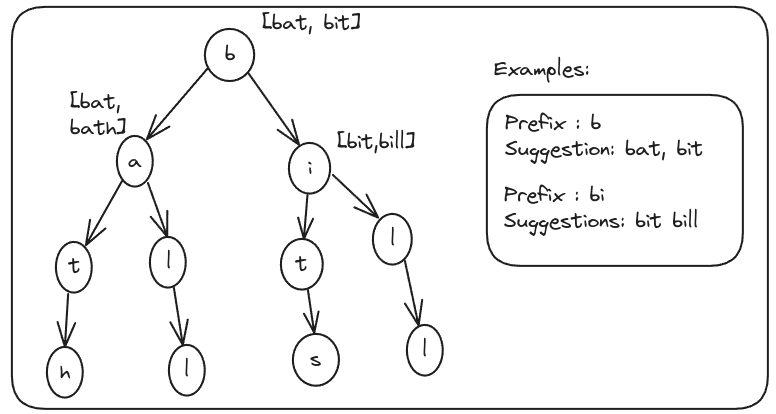
Suffix Tree
A compressed trie containing all suffixes of a text string, enabling O(m) time pattern matching where m is the pattern length.
- Space complexity: O(n) where n is text length
- Construction time: O(n) using Ukkonen's algorithm
- Supports multiple pattern searches efficiently
- Enables longest common substring queries
- Perfect for Kindle's prefix-based search suggestions
Suffix Array
Space-efficient alternative to suffix trees, storing sorted array of all suffix start positions with O(m log n) search time.
- Space complexity: O(n) - more memory efficient than suffix trees
- Construction: O(n log n) time using advanced algorithms
- Binary search enables fast pattern location
- Ideal for Kindle's memory-constrained devices
- Supports range queries for phrase matching
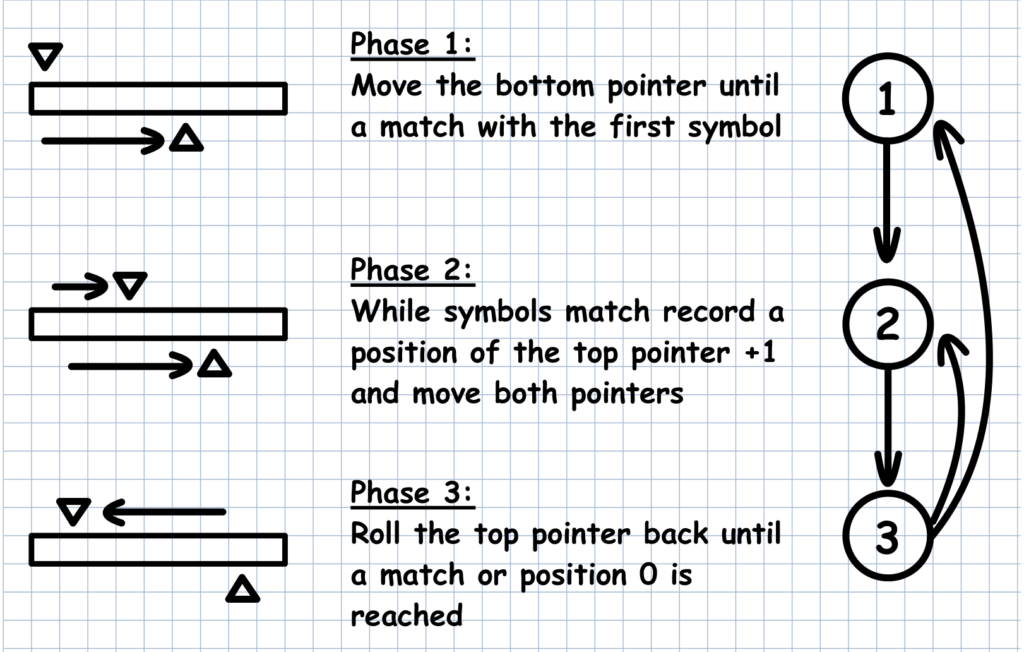
KMP Algorithm
Knuth-Morris-Pratt algorithm provides O(n + m) time string matching with optimal preprocessing for pattern analysis.
- Linear time complexity: O(n + m)
- No backtracking in the text
- Preprocessing creates failure function in O(m)
- Perfect for real-time search as users type
- Handles overlapping pattern occurrences efficiently
Applications in Amazon's Ecosystem
Kindle E-Reader Search
Kindle devices use optimized string algorithms for instant text search across downloaded books:
- Fast Offline Search: Compressed suffix arrays enable searches without internet connectivity, optimized for e-reader hardware constraints
- Context-Rich Results: KMP algorithm provides surrounding text snippets for each match, enhancing reading experience with relevant context
Kindle Mobile Search Ecosystem
iOS and Android Kindle apps leverage cloud-based search with local caching:
- Real-Time & Cross-Book Search: KMP streaming provides instant feedback as users type, while suffix trees enable searching across entire digital library
- Enhanced User Experience: Fuzzy matching handles typos and approximate matches, with visual highlighting powered by efficient pattern matching algorithms
Look Inside Feature
Amazon's book preview feature uses string search for content discovery:
- Content Indexing & Relevance: Suffix trees for rapid indexing of book previews with pattern frequency analysis using LCP arrays for relevance ranking
- Discovery & Recommendations: Efficient detection of memorable passages and quotes, while finding related content across different books to enhance browsing experience
Performance Metrics
Suffix Tree Complexity
Search time where m is pattern length, with O(n) space complexity
Suffix Array Complexity
Search time for pattern of length m in text of length n
KMP Complexity
Linear time complexity for text of length n and pattern of length m
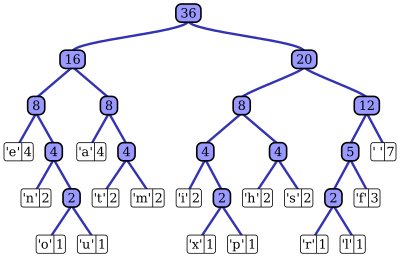
Suffix Tree Visualization
KMP Algorithm Visualization